Integration
1. Overview
OptaPlanner’s input and output data (the planning problem and the best solution) are plain old JavaBeans (POJOs), so integration with other Java technologies is straightforward. For example:
-
To read a planning problem from the database (and store the best solution in it), annotate the domain POJOs with JPA annotations.
-
To read a planning problem from an XML file (and store the best solution in it), annotate the domain POJOs with JAXB annotations.
-
To expose the Solver as a REST Service that reads the planning problem and responds with the best solution, annotate the domain POJOs with JAXB or Jackson annotations and hook the
Solverin Camel or RESTEasy.
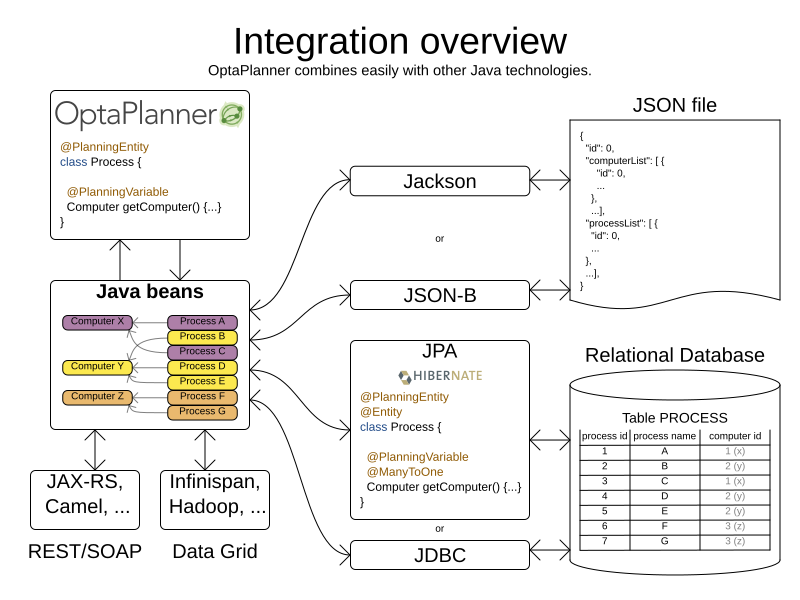
2. Persistent storage
2.1. Database: JPA and Hibernate
Enrich domain POJOs (solution, entities and problem facts) with JPA annotations
to store them in a database by calling EntityManager.persist().
|
Do not confuse JPA’s |
2.1.1. JPA and Hibernate: persisting a Score
The optaplanner-persistence-jpa jar provides a JPA score converter for every built-in score type.
@PlanningSolution
@Entity
public class CloudBalance {
@PlanningScore
@Convert(converter = HardSoftScoreConverter.class)
protected HardSoftScore score;
...
}Please note that the converters make JPA and Hibernate serialize the score in a single VARCHAR column.
This has the disadvantage that the score cannot be used in a SQL or JPA-QL query to efficiently filter the results, for example to query all infeasible schedules.
To avoid this limitation, implement the CompositeUserType to persist each score level into a separate database table column.
2.1.2. JPA and Hibernate: planning cloning
In JPA and Hibernate, there is usually a @ManyToOne relationship from most problem fact classes to the planning solution class.
Therefore, the problem fact classes reference the planning solution class, which implies that when the solution is planning cloned, they need to be cloned too.
Use an @DeepPlanningClone on each such problem fact class to enforce that:
@PlanningSolution // OptaPlanner annotation
@Entity // JPA annotation
public class Conference {
@OneToMany(mappedBy="conference")
private List<Room> roomList;
...
}@DeepPlanningClone // OptaPlanner annotation: Force the default planning cloner to planning clone this class too
@Entity // JPA annotation
public class Room {
@ManyToOne
private Conference conference; // Because of this reference, this problem fact needs to be planning cloned too
}Neglecting to do this can lead to persisting duplicate solutions, JPA exceptions or other side effects.
2.2. XML or JSON: JAXB
Enrich domain POJOs (solution, entities and problem facts) with JAXB annotations to serialize them to/from XML or JSON.
Add a dependency to the optaplanner-persistence-jaxb jar to take advantage of these extra integration features:
2.2.1. JAXB: marshalling a Score
When a Score is marshalled to XML or JSON by the default JAXB configuration, it’s corrupted.
To fix that, configure the appropriate ScoreJaxbAdapter:
@PlanningSolution
@XmlRootElement @XmlAccessorType(XmlAccessType.FIELD)
public class CloudBalance {
@PlanningScore
@XmlJavaTypeAdapter(HardSoftScoreJaxbAdapter.class)
private HardSoftScore score;
...
}For example, this generates pretty XML:
<cloudBalance>
...
<score>0hard/-200soft</score>
</cloudBalance>The same applies for a bendable score:
@PlanningSolution
@XmlRootElement @XmlAccessorType(XmlAccessType.FIELD)
public class Schedule {
@PlanningScore
@XmlJavaTypeAdapter(BendableScoreJaxbAdapter.class)
private BendableScore score;
...
}For example, with a hardLevelsSize of 2 and a softLevelsSize of 3, that will generate:
<schedule>
...
<score>[0/0]hard/[-100/-20/-3]soft</score>
</schedule>The hardLevelsSize and softLevelsSize implied, when reading a bendable score from an XML element, must always be in sync with those in the solver.
2.3. JSON: Jackson
Enrich domain POJOs (solution, entities and problem facts) with Jackson annotations to serialize them to/from JSON.
Add a dependency to the optaplanner-persistence-jackson jar and register OptaPlannerJacksonModule:
ObjectMapper objectMapper = new ObjectMapper();
objectMapper.registerModule(OptaPlannerJacksonModule.createModule());2.3.1. Jackson: marshalling a Score
When a Score is marshalled to/from JSON by the default Jackson configuration, it fails.
The OptaPlannerJacksonModule fixes that, by using HardSoftScoreJacksonSerializer,
HardSoftScoreJacksonDeserializer, etc.
@PlanningSolution
public class CloudBalance {
@PlanningScore
private HardSoftScore score;
...
}For example, this generates:
{
"score":"0hard/-200soft"
...
}|
When reading a This JSON implies the |
When a field is the Score supertype (instead of a specific type such as HardSoftScore), it uses PolymorphicScoreJacksonSerializer and PolymorphicScoreJacksonDeserializer
to record the score type in JSON too, otherwise it would be impossible to deserialize it:
@PlanningSolution
public class CloudBalance {
@PlanningScore
private Score score;
...
}For example, this generates:
{
"score":{"HardSoftScore":"0hard/-200soft"}
...
}2.4. JSON: JSON-B
Enrich domain POJOs (solution, entities and problem facts) with JSON-B annotations to serialize them to/from JSON.
Add a dependency to the optaplanner-persistence-jsonb jar and use OptaPlannerJsonbConfig to create a Jsonb instance:
JsonbConfig config = OptaPlannerJsonbConfig.createConfig();
Jsonb jsonb = JsonbBuilder.create(config);2.4.1. JSON-B: marshalling a Score
When a Score is marshalled to/from JSON by the default JSON-B configuration, it fails.
The OptaPlannerJsonbConfig fixes that, by using adapters including BendableScoreJsonbAdapter, HardSoftScoreJsonbAdapter, etc.
@PlanningSolution
public class CloudBalance {
@PlanningScore
private HardSoftScore score;
...
}For example, this generates:
{"hardSoftScore":"0hard/-200soft"}The same applies for a bendable score:
@PlanningSolution
public class CloudBalance {
@PlanningScore
private BendableScore score;
...
}This generates:
{"bendableScore":"[0/0]hard/[-200/-20/0]soft"}3. Quarkus
To use OptaPlanner with Quarkus, read the Quarkus Java quick start. If you are starting a new project, visit the code.quarkus.io and select the OptaPlanner AI constraint solver extension before generating your application.
|
Drools score calculation is incompatible with the |
Following properties are supported in the Quarkus application.properties:
- quarkus.optaplanner.solver-manager.parallel-solver-count
-
The number of solvers that run in parallel. This directly influences CPU consumption. Defaults to
AUTO. - quarkus.optaplanner.solver-config-xml
-
A classpath resource to read the solver configuration XML. Defaults to
solverConfig.xml. If this property isn’t specified, that file is optional. - quarkus.optaplanner.score-drl (deprecated)
-
A classpath resource to read the score DRL. Defaults to
constraints.drl. Do not define this property when aConstraintProvider,EasyScoreCalculatororIncrementalScoreCalculatorclass exists. - quarkus.optaplanner.solver.environment-mode
-
Enable runtime assertions to detect common bugs in your implementation during development.
- quarkus.optaplanner.solver.daemon
-
Enable daemon mode. In daemon mode, non-early termination pauses the solver instead of stopping it, until the next problem fact change arrives. This is often useful for real-time planning. Defaults to
false. - quarkus.optaplanner.solver.move-thread-count
-
Enable multithreaded solving for a single problem, which increases CPU consumption. Defaults to
NONE. See multithreaded incremental solving. - quarkus.optaplanner.solver.domain-access-type
-
How OptaPlanner should access the domain model. See the domain access section for more details. Defaults to
GIZMO. The other possible value isREFLECTION. - quarkus.optaplanner.solver.constraint-stream-impl-type
-
What Constraint Stream implementation to use. See the variant implementation types section for more details. Defaults to
DROOLS. The other possible value isBAVET. - quarkus.optaplanner.solver.termination.spent-limit
-
How long the solver can run. For example:
30sis 30 seconds.5mis 5 minutes.2his 2 hours.1dis 1 day. - quarkus.optaplanner.solver.termination.unimproved-spent-limit
-
How long the solver can run without finding a new best solution after finding a new best solution. For example:
30sis 30 seconds.5mis 5 minutes.2his 2 hours.1dis 1 day. - quarkus.optaplanner.solver.termination.best-score-limit
-
Terminates the solver when a specific or higher score has been reached. For example:
0hard/-1000softterminates when the best score changes from0hard/-1200softto0hard/-900soft. Wildcards are supported to replace numbers. For example:0hard/*softto terminate when any feasible score is reached. - quarkus.optaplanner.benchmark.solver-benchmark-config-xml
-
A classpath resource to read the benchmark configuration XML. Defaults to solverBenchmarkConfig.xml. If this property isn’t specified, that solverBenchmarkConfig.xml is optional.
- quarkus.optaplanner.benchmark.result-directory
-
Where the benchmark results are written to. Defaults to target/benchmarks.
- quarkus.optaplanner.benchmark.solver.termination.spent-limit
-
How long solver should be run in a benchmark run. For example:
30sis 30 seconds.5mis 5 minutes.2his 2 hours.1dis 1 day. Also supports ISO-8601 format, see Duration.
4. Spring Boot
To use OptaPlanner on Spring Boot, add the optaplanner-spring-boot-starter dependency
and read the Spring Boot Java quick start.
|
Drools score calculation is currently incompatible with the dependency |
These properties are supported in Spring’s application.properties:
- optaplanner.solver-manager.parallel-solver-count
-
The number of solvers that run in parallel. This directly influences CPU consumption. Defaults to
AUTO. - optaplanner.solver-config-xml
-
A classpath resource to read the solver configuration XML. Defaults to
solverConfig.xml. If this property isn’t specified, that file is optional. - optaplanner.score-drl (deprecated)
-
A classpath resource to read the score DRL. Defaults to
constraints.drl. Do not define this property when aConstraintProvider,EasyScoreCalculatororIncrementalScoreCalculatorclass exists. - optaplanner.solver.environment-mode
-
Enable runtime assertions to detect common bugs in your implementation during development.
- optaplanner.solver.daemon
-
Enable daemon mode. In daemon mode, non-early termination pauses the solver instead of stopping it, until the next problem fact change arrives. This is often useful for real-time planning. Defaults to
false. - optaplanner.solver.move-thread-count
-
Enable multithreaded solving for a single problem, which increases CPU consumption. Defaults to
NONE. See multithreaded incremental solving. - optaplanner.solver.domain-access-type
-
How OptaPlanner should access the domain model. See the domain access section for more details. Defaults to
REFLECTION. The other possible value isGIZMO. - optaplanner.solver.constraint-stream-impl-type
-
What Constraint Stream implementation to use. See the variant implementation types section for more details. Defaults to
DROOLS. The other possible value isBAVET. - optaplanner.solver.termination.spent-limit
-
How long the solver can run. For example:
30sis 30 seconds.5mis 5 minutes.2his 2 hours.1dis 1 day. - optaplanner.solver.termination.unimproved-spent-limit
-
How long the solver can run without finding a new best solution after finding a new best solution. For example:
30sis 30 seconds.5mis 5 minutes.2his 2 hours.1dis 1 day. - optaplanner.solver.termination.best-score-limit
-
Terminates the solver when a specific or higher score has been reached. For example:
0hard/-1000softterminates when the best score changes from0hard/-1200softto0hard/-900soft. Wildcards are supported to replace numbers. For example:0hard/*softto terminate when any feasible score is reached. - optaplanner.benchmark.solver-benchmark-config-xml
-
A classpath resource to read the benchmark configuration XML. Defaults to solverBenchmarkConfig.xml. If this property isn’t specified, that solverBenchmarkConfig.xml is optional.
- optaplanner.benchmark.result-directory
-
Where the benchmark results are written to. Defaults to target/benchmarks.
- optaplanner.benchmark.solver.termination.spent-limit
-
How long solver should be run in a benchmark run. For example:
30sis 30 seconds.5mis 5 minutes.2his 2 hours.1dis 1 day. Also supports ISO-8601 format, see Duration.
5. SOA and ESB
5.1. Camel and Karaf
Camel is an enterprise integration framework which includes support for OptaPlanner (starting from Camel 2.13). It can expose a use case as a REST service, a SOAP service, a JMS service, …
Read the documentation for the camel-optaplanner component. That component works in Karaf too.
6. Other environments
6.1. Java platform module system (Jigsaw)
When using OptaPlanner from code on the modulepath (Java 9 and higher),
open your packages that contain your domain objects, constraints and solver configuration
to all modules in your module-info.java file:
module org.optaplanner.cloudbalancing {
requires org.optaplanner.core;
...
opens org.optaplanner.examples.cloudbalancing; // Solver configuration
opens org.optaplanner.examples.cloudbalancing.domain; // Domain classes
opens org.optaplanner.examples.cloudbalancing.score; // Constraints
...
}Otherwise OptaPlanner can’t reach those classes or files, even if they are exported.
6.3. Android
Android is not a complete JVM (because some JDK libraries are missing), but OptaPlanner works on Android with easy Java or incremental Java score calculation. The Drools rule engine does not work on Android yet, so Constraint Streams and Drools score calculation (Deprecated) doesn’t work on Android and its dependencies need to be excluded.
Workaround to use OptaPlanner on Android:
-
Add a dependency to the
build.gradlefile in your Android project to exclude OptaPlanner’soptaplanner-constraint-streams-droolsandoptaplanner-constraint-drlmodules:dependencies { ... implementation('org.optaplanner:optaplanner-core:...') { exclude group: 'org.optaplanner', module: 'optaplanner-constraint-streams-drools' exclude group: 'org.optaplanner', module: 'optaplanner-constraint-drl' } ... }
7. Integration with human planners (politics)
A good OptaPlanner implementation beats any good human planner for non-trivial datasets. Many human planners fail to accept this, often because they feel threatened by an automated system.
But despite that, both can benefit if the human planner becomes the supervisor of OptaPlanner:
-
The human planner defines, validates and tweaks the score function.
-
The human planner tweaks the constraint weights of the constraint configuration in a UI, as the business priorities change over time.
-
When the business changes, the score function often needs to change too. The human planner can notify the developers to add, change or remove score constraints.
-
-
The human planner is always in control of OptaPlanner.
-
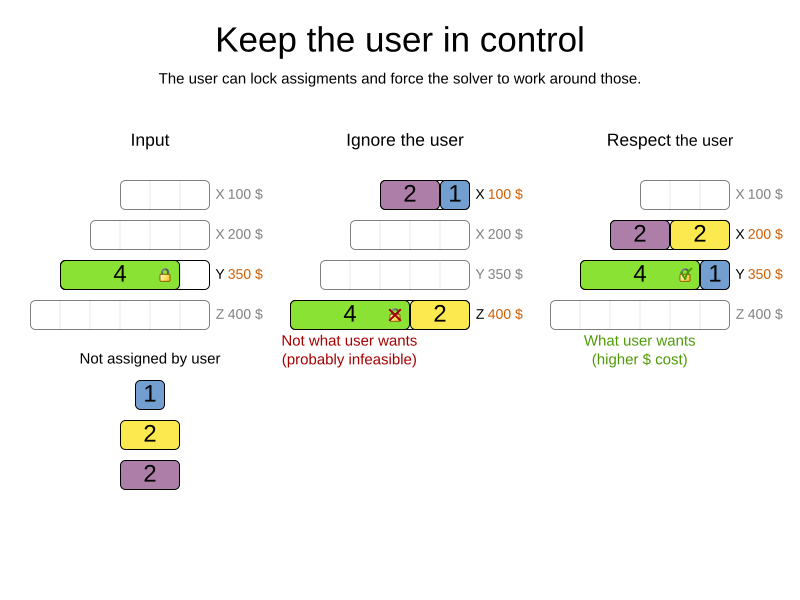
As shown in the course scheduling example, the human planner can pin down one or more planning variables to a specific planning value. Because they are pinned, OptaPlanner does not change them: it optimizes the planning around the enforcements made by the human. If the human planner pins down all planning variables, he/she sidelines OptaPlanner completely.
-
In a prototype implementation, the human planner occasionally uses pinning to intervene, but as the implementation matures, this should become obsolete. The feature should be kept available as a reassurance for the humans, and in the event that the business changes dramatically before the score constraints are adjusted accordingly.
-
For this reason, it is recommended that the human planner is actively involved in your project.
8. Sizing hardware and software
Before sizing a OptaPlanner service, first understand the typical behaviour of a Solver.solve() call:
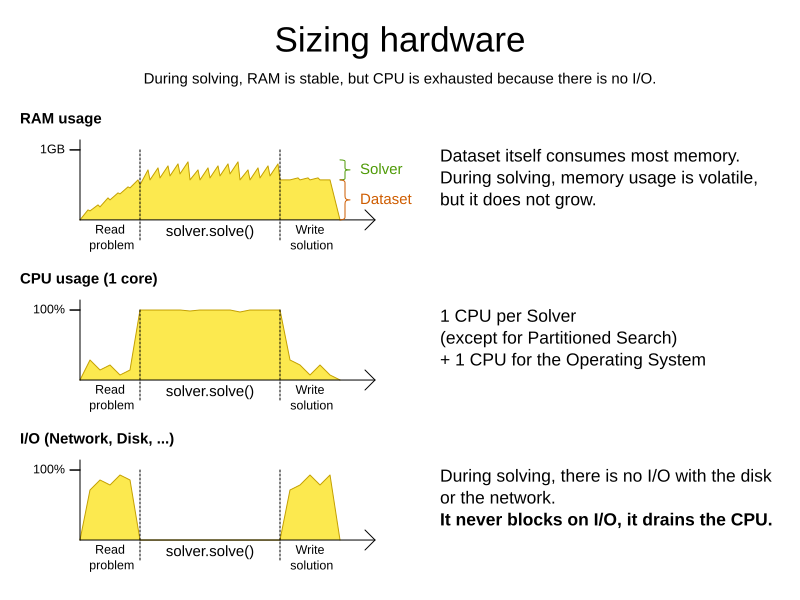
Understand these guidelines to decide the hardware for a OptaPlanner service:
-
RAM memory: Provision plenty, but no need to provide more.
-
The problem dataset, loaded before OptaPlanner is called, often consumes the most memory. It depends on the problem scale.
-
For example, in the Machine Reassignment example some datasets use over 1GB in memory. But in most examples, they use just a few MB.
-
If this is a problem, review the domain class structure: remove classes or fields that OptaPlanner doesn’t need during solving.
-
OptaPlanner usually has up to three solution instances: the internal working solution, the best solution and the old best solution (when it’s being replaced). However, these are all a planning clone of each other, so many problem fact instances are shared between those solution instances.
-
-
During solving, the memory is very volatile, because solving creates many short-lived objects. The Garbage Collector deletes these in bulk and therefore needs some heap space as a buffer.
-
The maximum size of the JVM heap space can be in three states:
-
Insufficient: An
OutOfMemoryExceptionis thrown (often because the Garbage Collector is using more than 98% of the CPU time). -
Narrow: The heap buffer for those short-lived instances is too small, therefore the Garbage Collector needs to run more than it would like to, which causes a performance loss.
-
Profiling shows that in the heap chart, the used heap space frequently touches the max heap space during solving. It also shows that the Garbage Collector has a significant CPU usage impact.
-
Adding more heap space increases the score calculation speed.
-
-
Plenty: There is enough heap space. The Garbage Collector is active, but its CPU usage is low.
-
Adding more heap space does not increase performance.
-
Usually, this is around 300 to 500MB above the dataset size, regardless of the problem scale (except with nearby selection and caching move selector, neither are used by default).
-
-
-
-
CPU power: More is better.
-
Improving CPU speed directly increases the score calculation speed.
-
If the CPU power is twice as fast, it takes half the time to find the same result. However, this does not guarantee that it finds a better result in the same time, nor that it finds a similar result for a problem twice as big in the same time.
-
Increasing CPU power usually does not resolve scaling issues, because planning problems scale exponentially. Power tweaking the solver configuration has far better results for scaling issues than throwing hardware at it.
-
-
During the
solve()method, the CPU power will max out until it returns (except in daemon mode or if your SolverEventListener writes the best solution to disk or the network).
-
-
Number of CPU cores: one CPU core per active Solver, plus at least one one for the operating system.
-
So in a multitenant application, which has one Solver per tenant, this means one CPU core per tenant, unless the number of solver threads is limited, as that limits the number of tenants being solved in parallel.
-
With Partitioned Search, presume one CPU core per partition (per active tenant), unless the number of partition threads is limited.
-
To reduce the number of used cores, it can be better to reduce the partition threads (so solve some partitions sequentially) than to reduce the number of partitions.
-
-
In use cases with many tenants (such as scheduling Software as a Service) or many partitions, it might not be affordable to provision that many CPUs.
-
Reduce the number of active Solvers at a time. For example: give each tenant only one minute of machine time and use a
ExecutorServicewith a fixed thread pool to queue requests. -
Distribute the Solver runs across the day (or night). This is especially an opportunity in SaaS that’s used across the globe, due to timezones: UK and India can use the same CPU core when scheduling at night.
-
-
The SolverManager will take care of the orchestration, especially in those underfunded environments in which solvers (and partitions) are forced to share CPU cores or wait in line.
-
-
I/O (network, disk, …): Not used during solving.
-
OptaPlanner is not a web server: a solver thread does not block (unlike a servlet thread), each one fully drains a CPU.
-
A web server can handle 24 active servlets threads with eight cores without performance loss, because most servlets threads are blocking on I/O.
-
However, 24 active solver threads with eight cores will cause each solver’s score calculation speed to be three times slower, causing a big performance loss.
-
-
Note that calling any I/O during solving, for example a remote service in your score calculation, causes a huge performance loss because it’s called thousands of times per second, so it should complete in microseconds. So no good implementation does that.
-
Keep these guidelines in mind when selecting and configuring the software. See our blog archive for the details of our experiments, which use our diverse set of examples. Your mileage may vary.
-
Operating System
-
No experimentally proven advice yet (but prefer Linux anyway).
-
-
JDK
-
Version: Our benchmarks have consistently shown improvements in performance when comparing new JDK releases with their predecessors. It is therefore recommended using the latest available JDK. If you’re interested in the performance comparisons of OptaPlanner running of different JDK releases, you can find them in the form of blog posts in our blog archive.
-
Garbage Collector: ParallelGC can be potentially between 5% and 35% faster than G1GC (the default). Unlike web servers, OptaPlanner needs a GC focused on throughput, not latency. Use
-XX:+UseParallelGCto turn on ParallelGC.
-
-
Logging can have a severe impact on performance.
-
Debug logging
org.droolscan reduce performance by a factor of 7. -
Debug logging
org.optaplannercan be between 0% and 15% slower than info logging. Trace logging can be between 5% and 70% slower than info logging. -
Synchronous logging to a file has an additional significant impact for debug and trace logging (but not for info logging).
-
-
Avoid a cloud environment in which you share your CPU core(s) with other virtual machines or containers. Performance (and therefore solution quality) can be unreliable when the available CPU power varies greatly.
Keep in mind that the perfect hardware/software environment will probably not solve scaling issues (even Moore’s law is too slow). There is no need to follow these guidelines to the letter.