Constraint streams score calculation
Constraint streams are a Functional Programming form of incremental score calculation in plain Java that is easy to read, write and debug. The API should feel familiar if you’re familiar with Java Streams or SQL.
1. Introduction
Using Java’s Streams API, we could implement an easy score calculator that uses a functional approach:
private int doNotAssignAnn() {
int softScore = 0;
schedule.getShiftList().stream()
.filter(Shift::isEmployeeAnn)
.forEach(shift -> {
softScore -= 1;
});
return softScore;
}However, that scales poorly because it doesn’t do an incremental calculation:
When the planning variable of a single Shift changes, to recalculate the score,
the normal Streams API has to execute the entire stream from scratch.
The ConstraintStreams API enables you to write similar code in pure Java, while reaping the performance benefits of
incremental score calculation.
This is an example of the same code, using the Constraint Streams API:
private Constraint doNotAssignAnn(ConstraintFactory factory) {
return factory.forEach(Shift.class)
.filter(Shift::isEmployeeAnn)
.penalize(HardSoftScore.ONE_SOFT)
.asConstraint("Don't assign Ann");
}This constraint stream iterates over all instances of class Shift in the problem facts and
planning entities in the planning problem.
It finds every Shift which is assigned to employee Ann and for every such instance (also called a match), it adds a
soft penalty of 1 to the overall score.
The following figure illustrates this process on a problem with 4 different shifts:
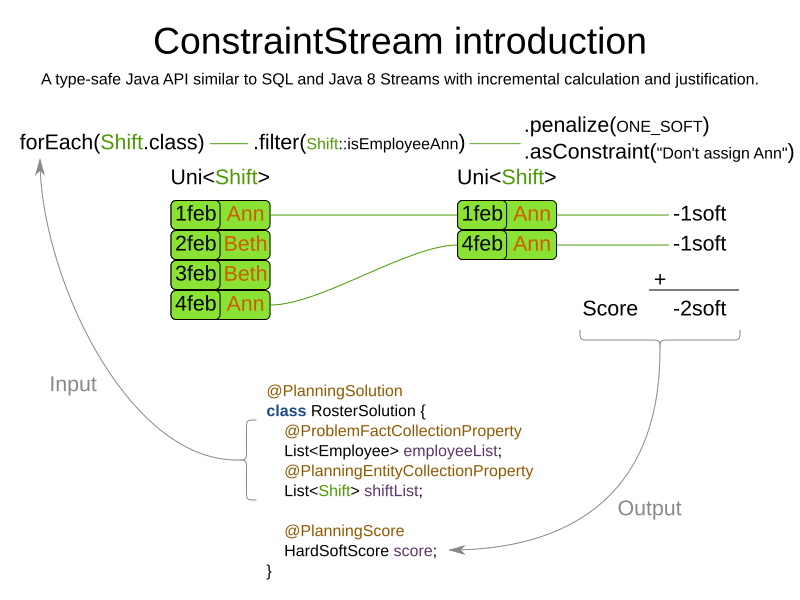
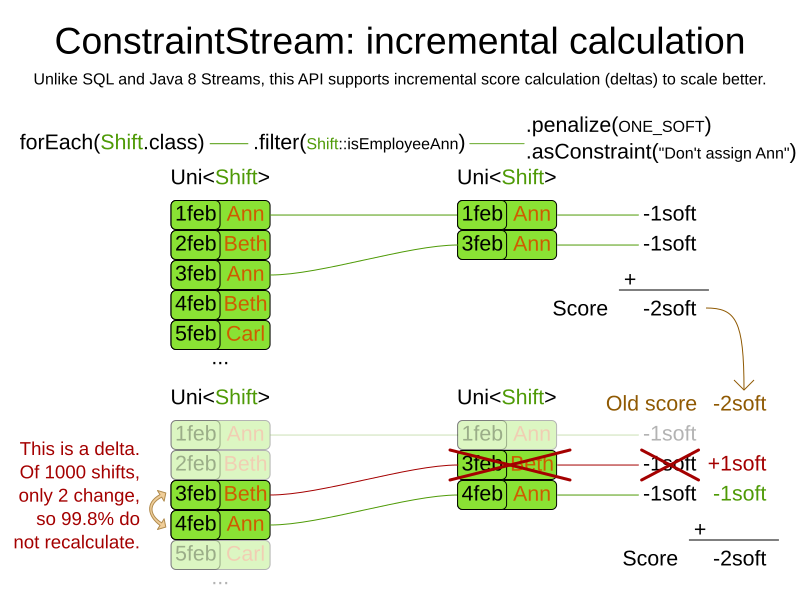
If any of the instances change during solving, the constraint stream automatically detects the change and only recalculates the minimum necessary portion of the problem that is affected by the change. The following figure illustrates this incremental score calculation:
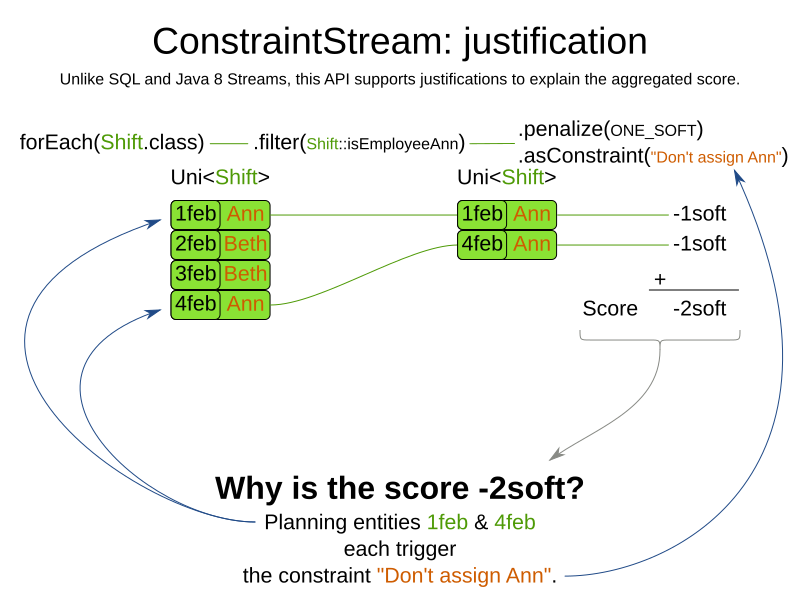
ConstraintStreams API also has advanced support for score explanation through custom justifications and indictments.
2. Creating a constraint stream
To use the ConstraintStreams API in your project, first write a pure Java ConstraintProvider implementation similar
to the following example.
public class MyConstraintProvider implements ConstraintProvider {
@Override
public Constraint[] defineConstraints(ConstraintFactory factory) {
return new Constraint[] {
penalizeEveryShift(factory)
};
}
private Constraint penalizeEveryShift(ConstraintFactory factory) {
return factory.forEach(Shift.class)
.penalize(HardSoftScore.ONE_SOFT)
.asConstraint("Penalize a shift");
}
}|
This example contains one constraint, |
Add the following code to your solver configuration:
<solver xmlns="https://www.optaplanner.org/xsd/solver" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="https://www.optaplanner.org/xsd/solver https://www.optaplanner.org/xsd/solver/solver.xsd">
<scoreDirectorFactory>
<constraintProviderClass>org.acme.schooltimetabling.solver.TimeTableConstraintProvider</constraintProviderClass>
</scoreDirectorFactory>
...
</solver>3. Constraint stream cardinality
Constraint stream cardinality is a measure of how many objects a single constraint match consists of.
The simplest constraint stream has a cardinality of 1, meaning each constraint match only consists of 1 object.
Therefore, it is called a UniConstraintStream:
private Constraint doNotAssignAnn(ConstraintFactory factory) {
return factory.forEach(Shift.class) // Returns UniStream<Shift>.
...
}Some constraint stream building blocks can increase stream cardinality, such as join or groupBy:
private Constraint doNotAssignAnn(ConstraintFactory factory) {
return factory.forEach(Shift.class) // Returns Uni<Shift>.
.join(Employee.class) // Returns Bi<Shift, Employee>.
.join(DayOff.class) // Returns Tri<Shift, Employee, DayOff>.
.join(Country.class) // Returns Quad<Shift, Employee, DayOff, Country>.
...
}The latter can also decrease stream cardinality:
private Constraint doNotAssignAnn(ConstraintFactory factory) {
return factory.forEach(Shift.class) // Returns UniStream<Shift>.
.join(Employee.class) // Returns BiStream<Shift, Employee>.
.groupBy((shift, employee) -> employee) // Returns UniStream<Employee>.
...
}The following constraint stream cardinalities are currently supported:
Cardinality |
Prefix |
Defining interface |
1 |
Uni |
|
2 |
Bi |
|
3 |
Tri |
|
4 |
Quad |
|
3.1. Achieving higher cardinalities
OptaPlanner currently does not support constraint stream cardinalities higher than 4. However, with tuple mapping effectively infinite cardinality is possible:
private Constraint pentaStreamExample(ConstraintFactory factory) {
return factory.forEach(Shift.class) // UniConstraintStream<Shift>
.join(Shift.class) // BiConstraintStream<Shift, Shift>
.join(Shift.class) // TriConstraintStream<Shift, Shift, Shift>
.join(Shift.class) // QuadConstraintStream<Shift, Shift, Shift, Shift>
.map(MyTuple::of) // UniConstraintStream<MyTuple<Shift, Shift, Shift, Shift>>
.join(Shift.class) // BiConstraintStream<MyTuple<Shift, Shift, Shift, Shift>, Shift>
... // This BiConstraintStream carries 5 Shift elements.
}|
OptaPlanner does not provide any tuple implementations out of the box. It’s recommended to use one of the freely available 3rd party implementations. Should a custom implementation be necessary, see guidelines for mapping functions. |
4. Building blocks
Constraint streams are chains of different operations, called building blocks.
Each constraint stream starts with a forEach(…) building block and is terminated by either a penalty or a reward.
The following example shows the simplest possible constraint stream:
private Constraint penalizeInitializedShifts(ConstraintFactory factory) {
return factory.forEach(Shift.class)
.penalize(HardSoftScore.ONE_SOFT)
.asConstraint("Initialized shift");
}This constraint stream penalizes each known and initialized instance of Shift.
4.1. ForEach
The .forEach(T) building block selects every T instance that
is in a problem fact collection
or a planning entity collection
and has no null genuine planning variables.
To include instances with a null genuine planning variable,
replace the forEach() building block by forEachIncludingNullVars():
private Constraint penalizeAllShifts(ConstraintFactory factory) {
return factory.forEachIncludingNullVars(Shift.class)
.penalize(HardSoftScore.ONE_SOFT)
.asConstraint("A shift");
}|
The |
4.2. Penalties and rewards
The purpose of constraint streams is to build up a score for a solution.
To do this, every constraint stream must contain a call to either a penalize() or a reward()
building block.
The penalize() building block makes the score worse and the reward() building block improves the score.
Each constraint stream is then terminated by calling asConstraint() method, which finally builds the constraint. Constraints have several components:
-
Constraint package is the Java package that contains the constraint. The default value is the package that contains the
ConstraintProviderimplementation or the value from constraint configuration, if implemented. -
Constraint name is the human-readable descriptive name for the constraint, which (together with the constraint package) must be unique within the entire
ConstraintProviderimplementation. -
Constraint weight is a constant score value indicating how much every breach of the constraint affects the score. Valid examples include
SimpleScore.ONE,HardSoftScore.ONE_HARDandHardMediumSoftScore.of(1, 2, 3). -
Constraint match weigher is an optional function indicating how many times the constraint weight should be applied in the score. The penalty or reward score impact is the constraint weight multiplied by the match weight. The default value is
1.
|
Constraints with zero constraint weight are automatically disabled and do not impose any performance penalty. |
The ConstraintStreams API supports many different types of penalties. Browse the API in your IDE for the full list of method overloads. Here are some examples:
-
Simple penalty (
penalize(SimpleScore.ONE)) makes the score worse by1per every match in the constraint stream. The score type must be the same type as used on the@PlanningScoreannotated member on the planning solution. -
Dynamic penalty (
penalize(SimpleScore.ONE, Shift::getHours)) makes the score worse by the number of hours in every matchingShiftin the constraint stream. This is an example of using a constraint match weigher. -
Configurable penalty (
penalizeConfigurable()) makes the score worse using constraint weights defined in constraint configuration. -
Configurable dynamic penalty(
penalizeConfigurable(Shift::getHours)) makes the score worse using constraint weights defined in constraint configuration, multiplied by the number of hours in every matchingShiftin the constraint stream.
By replacing the keyword penalize by reward in the name of these building blocks, you get operations that
affect score in the opposite direction.
4.2.1. Customizing justifications and indictments
One of important OptaPlanner features is its ability to explain the score of solutions it produced through the use of justifications and indictments.
By default, each constraint is justified with org.optaplanner.core.api.score.stream.DefaultConstraintJustification, and the final tuple makes up the indicted objects.
For example, in the following constraint, the indicted objects will be of type Vehicle and an Integer:
protected Constraint vehicleCapacity(ConstraintFactory factory) {
return factory.forEach(Customer.class)
.filter(customer -> customer.getVehicle() != null)
.groupBy(Customer::getVehicle, sum(Customer::getDemand))
.filter((vehicle, demand) -> demand > vehicle.getCapacity())
.penalizeLong(HardSoftLongScore.ONE_HARD,
(vehicle, demand) -> demand - vehicle.getCapacity())
.asConstraint("vehicleCapacity");
}For the purposes of creating a heat map, the Vehicle is very important, but the naked Integer carries no semantics.
We can remove it by providing the `indictWith(…) method with a custom indictment mapping:
protected Constraint vehicleCapacity(ConstraintFactory factory) {
return factory.forEach(Customer.class)
.filter(customer -> customer.getVehicle() != null)
.groupBy(Customer::getVehicle, sum(Customer::getDemand))
.filter((vehicle, demand) -> demand > vehicle.getCapacity())
.penalizeLong(HardSoftLongScore.ONE_HARD,
(vehicle, demand) -> demand - vehicle.getCapacity())
.indictWith((vehicle, demand) -> List.of(vehicle))
.asConstraint("vehicleCapacity");
}The same mechanism can also be used to transform any of the indicted objects to any other object.
To present the constraint matches to the user or to send them over the wire where they can be further processed, use the justifyWith(…) method to provide a custom constraint justification:
protected Constraint vehicleCapacity(ConstraintFactory factory) {
return factory.forEach(Customer.class)
.filter(customer -> customer.getVehicle() != null)
.groupBy(Customer::getVehicle, sum(Customer::getDemand))
.filter((vehicle, demand) -> demand > vehicle.getCapacity())
.penalizeLong(HardSoftLongScore.ONE_HARD,
(vehicle, demand) -> demand - vehicle.getCapacity())
.justifyWith((vehicle, demand, score) ->
new VehicleDemandOveruse(vehicle, demand, score))
.indictWith((vehicle, demand) -> List.of(vehicle))
.asConstraint("vehicleCapacity");
}VehicleDemandOveruse is a custom type you have to implement.
You have complete control over the type, its name or methods exposed.
If you choose to decorate it with the proper annotations,
you will be able to send it over HTTP or store it in a database.
The only limitation is that it must implement the org.optaplanner.core.api.score.stream.ConstraintJustification marker interface.
4.3. Filtering
Filtering enables you to reduce the number of constraint matches in your stream.
It first enumerates all constraint matches and then applies a predicate to filter some matches out.
The predicate is a function that only returns true if the match is to continue in the stream.
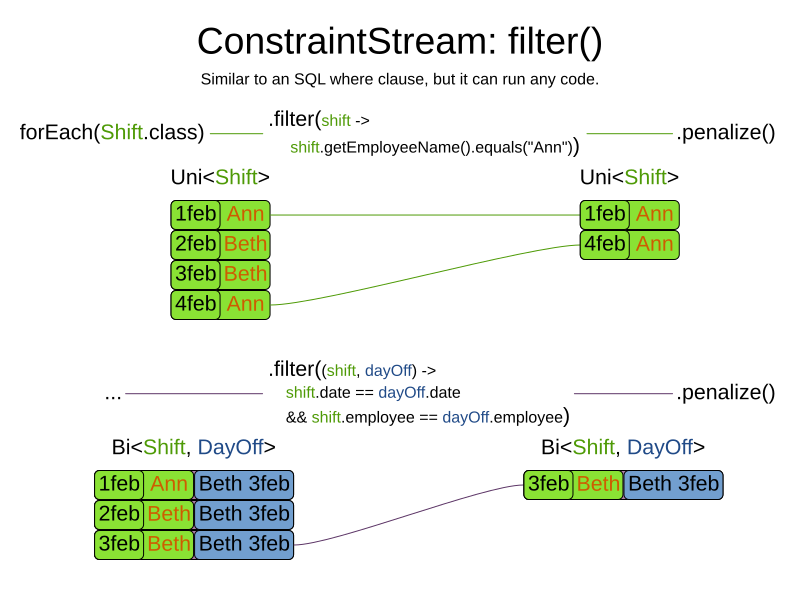
The following constraint stream removes all of Beth’s shifts from all Shift matches:
private Constraint penalizeAnnShifts(ConstraintFactory factory) {
return factory.forEach(Shift.class)
.filter(shift -> shift.getEmployeeName().equals("Ann"))
.penalize(SimpleScore.ONE)
.asConstraint("Ann's shift");
}The following example retrieves a list of shifts where an employee has asked for a day off from a bi-constraint match
of Shift and DayOff:
private Constraint penalizeShiftsOnOffDays(ConstraintFactory factory) {
return factory.forEach(Shift.class)
.join(DayOff.class)
.filter((shift, dayOff) -> shift.date == dayOff.date && shift.employee == dayOff.employee)
.penalize(SimpleScore.ONE)
.asConstraint("Shift on an off-day");
}The following figure illustrates both these examples:
|
For performance reasons, using the join building block with the appropriate |
The following functions are required for filtering constraint streams of different cardinality:
Cardinality |
Filtering Predicate |
1 |
|
2 |
|
3 |
|
4 |
|
4.4. Joining
Joining is a way to increase stream cardinality and it is similar to the inner join
operation in SQL. As the following figure illustrates,
a join() creates a cartesian product of the streams being joined:
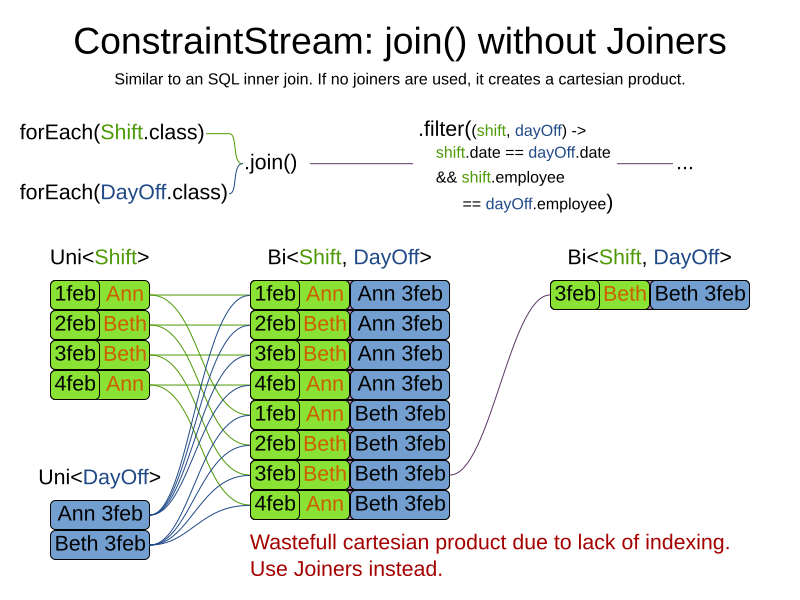
Doing this is inefficient if the resulting stream contains a lot of constraint matches that need to be filtered out immediately.
Instead, use a Joiner condition to restrict the joined matches only to those that are interesting:
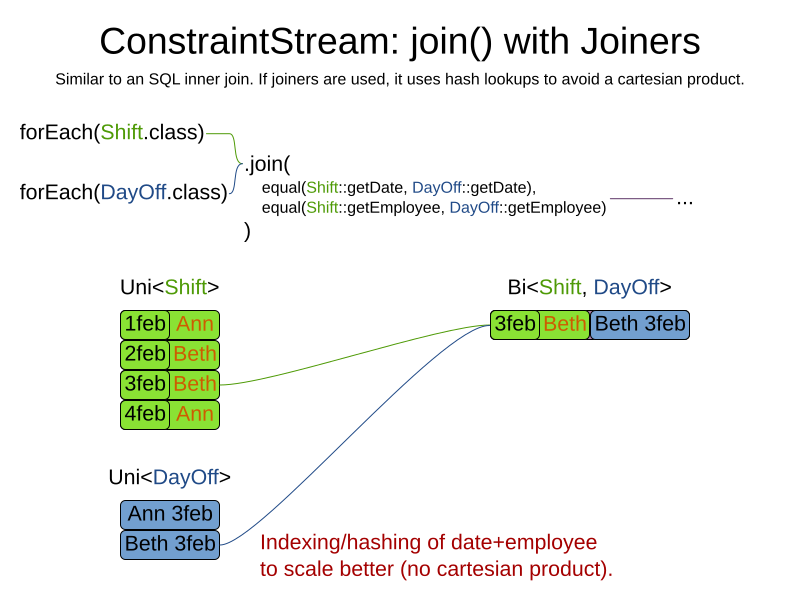
For example:
import static org.optaplanner.core.api.score.stream.Joiners.*;
...
private Constraint shiftOnDayOff(ConstraintFactory constraintFactory) {
return constraintFactory.forEach(Shift.class)
.join(DayOff.class,
equal(Shift::getDate, DayOff::getDate),
equal(Shift::getEmployee, DayOff::getEmployee))
.penalize(HardSoftScore.ONE_HARD)
.asConstraint("Shift on an off-day");
}Through the Joiners class, the following Joiner conditions are supported to join two streams,
pairing a match from each side:
-
equal(): the paired matches have a property that areequals(). This relies onhashCode(). -
greaterThan(),greaterThanOrEqual(),lessThan()andlessThanOrEqual(): the paired matches have aComparableproperty following the prescribed ordering. -
overlapping(): the paired matches have two properties (a start and an end property) of the sameComparabletype that both represent an interval which overlap.
All Joiners methods have an overloaded method to use the same property of the same class on both stream sides.
For example, calling equal(Shift::getEmployee) is the same as calling equal(Shift::getEmployee, Shift::getEmployee).
|
If the other stream might match multiple times, but it must only impact the score once (for each element of the original stream), use ifExists instead. It does not create cartesian products and therefore generally performs better. |
4.5. Grouping and collectors
Grouping collects items in a stream according to user-provider criteria (also called "group key"), similar to what a
GROUP BY SQL clause does. Additionally, some grouping operations also accept one or more Collector instances, which
provide various aggregation functions. The following figure illustrates a simple groupBy() operation:
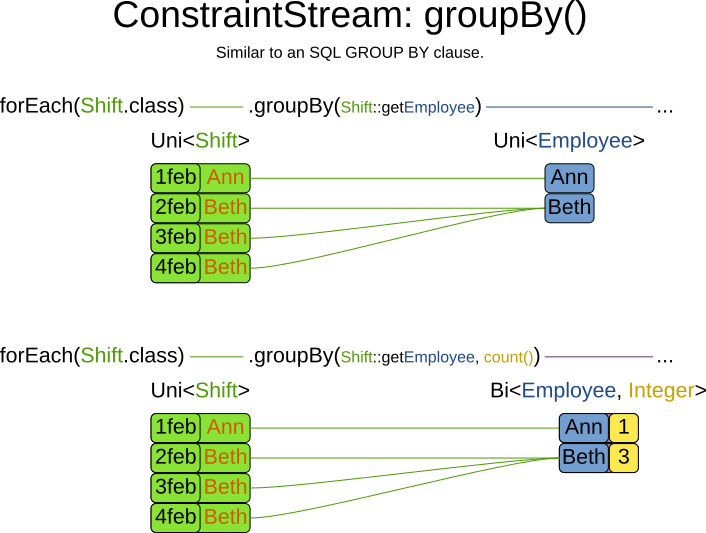
|
Objects used as group key must obey the general contract of For this reason, it is not recommended to use mutable objects (especially mutable collections) as group keys. If planning entities are used as group keys, their hashCode must not be computed off of planning variables. Failure to follow this recommendation may result in runtime exceptions being thrown. |
For example, the following code snippet first groups all processes by the computer they run on, sums up all the power
required by the processes on that computer using the ConstraintCollectors.sum(…) collector, and finally penalizes
every computer whose processes consume more power than is available.
import static org.optaplanner.core.api.score.stream.ConstraintCollectors.*;
...
private Constraint requiredCpuPowerTotal(ConstraintFactory constraintFactory) {
return constraintFactory.forEach(CloudProcess.class)
.groupBy(CloudProcess::getComputer, sum(CloudProcess::getRequiredCpuPower))
.filter((computer, requiredCpuPower) -> requiredCpuPower > computer.getCpuPower())
.penalize(HardSoftScore.ONE_HARD,
(computer, requiredCpuPower) -> requiredCpuPower - computer.getCpuPower())
.asConstraint("requiredCpuPowerTotal");
}|
Information might be lost during grouping.
In the previous example, |
There are several collectors available out of the box. You can also provide your own collectors by implementing the
org.optaplanner.core.api.score.stream.uni.UniConstraintCollector interface, or its Bi…, Tri… and Quad… counterparts.
4.5.1. Out-of-the-box collectors
The following collectors are provided out of the box:
count() collector
The ConstraintCollectors.count(…) counts all elements per group. For example, the following use of the collector
gives a number of items for two separate groups - one where the talks have unavailable speakers, and one where they
don’t.
private Constraint speakerAvailability(ConstraintFactory factory) {
return factory.forEach(Talk.class)
.groupBy(Talk::hasAnyUnavailableSpeaker, count())
.penalize(HardSoftScore.ONE_HARD,
(hasUnavailableSpeaker, count) -> ...)
.asConstraint("speakerAvailability");
}The count is collected in an int. Variants of this collector:
-
countLong()collects alongvalue instead of anintvalue.
To count a bi, tri or quad stream, use countBi(), countTri() or countQuad() respectively,
because - unlike the other built-in collectors - they aren’t overloaded methods due to Java’s generics erasure.
countDistinct() collector
The ConstraintCollectors.countDistinct(…) counts any element per group once, regardless of how many times it
occurs. For example, the following use of the collector gives a number of talks in each unique room.
private Constraint roomCount(ConstraintFactory factory) {
return factory.forEach(Talk.class)
.groupBy(Talk::getRoom, countDistinct())
.penalize(HardSoftScore.ONE_SOFT,
(room, count) -> ...)
.asConstraint("roomCount");
}The distinct count is collected in an int. Variants of this collector:
-
countDistinctLong()collects alongvalue instead of anintvalue.
sum() collector
To sum the values of a particular property of all elements per group, use the ConstraintCollectors.sum(…)
collector. The following code snippet first groups all processes by the computer they run on and sums up all the power
required by the processes on that computer using the ConstraintCollectors.sum(…) collector.
private Constraint requiredCpuPowerTotal(ConstraintFactory constraintFactory) {
return constraintFactory.forEach(CloudProcess.class)
.groupBy(CloudProcess::getComputer, sum(CloudProcess::getRequiredCpuPower))
.penalize(HardSoftScore.ONE_SOFT,
(computer, requiredCpuPower) -> requiredCpuPower)
.asConstraint("requiredCpuPowerTotal");
}The sum is collected in an int. Variants of this collector:
-
sumLong()collects alongvalue instead of anintvalue. -
sumBigDecimal()collects ajava.math.BigDecimalvalue instead of anintvalue. -
sumBigInteger()collects ajava.math.BigIntegervalue instead of anintvalue. -
sumDuration()collects ajava.time.Durationvalue instead of anintvalue. -
sumPeriod()collects ajava.time.Periodvalue instead of anintvalue. -
a generic
sum()variant for summing up custom types
average() collector
To calculate the average of a particular property of all elements per group, use the ConstraintCollectors.average(…)
collector.
The following code snippet first groups all processes by the computer they run on and averages all the power
required by the processes on that computer using the ConstraintCollectors.average(…) collector.
private Constraint requiredCpuPowerTotal(ConstraintFactory constraintFactory) {
return constraintFactory.forEach(CloudProcess.class)
.groupBy(CloudProcess::getComputer, average(CloudProcess::getRequiredCpuPower))
.penalize(HardSoftScore.ONE_SOFT,
(computer, averageCpuPower) -> averageCpuPower)
.asConstraint("averageCpuPower");
}The average is collected as a double, and the average of no elements is null.
Variants of this collector:
-
averageLong()collects alongvalue instead of anintvalue. -
averageBigDecimal()collects ajava.math.BigDecimalvalue instead of anintvalue, resulting in aBigDecimalaverage. -
averageBigInteger()collects ajava.math.BigIntegervalue instead of anintvalue, resulting in aBigDecimalaverage. -
averageDuration()collects ajava.time.Durationvalue instead of anintvalue, resulting in aDurationaverage.
min() and max() collectors
To extract the minimum or maximum per group, use the ConstraintCollectors.min(…) and
ConstraintCollectors.max(…) collectors respectively.
These collectors operate on values of properties which are Comparable (such as Integer, String or Duration),
although there are also variants of these collectors which allow you to provide your own Comparator.
The following example finds a computer which runs the most power-demanding process:
private Constraint computerWithBiggestProcess(ConstraintFactory constraintFactory) {
return constraintFactory.forEach(CloudProcess.class)
.groupBy(CloudProcess::getComputer, max(CloudProcess::getRequiredCpuPower))
.penalize(HardSoftScore.ONE_HARD,
(computer, biggestProcess) -> ...)
.asConstraint("computerWithBiggestProcess");
}|
|
toList(), toSet() and toMap() collectors
To extract all elements per group into a collection, use the ConstraintCollectors.toList(…).
The following example retrieves all processes running on a computer in a List:
private Constraint computerWithBiggestProcess(ConstraintFactory constraintFactory) {
return constraintFactory.forEach(CloudProcess.class)
.groupBy(CloudProcess::getComputer, toList())
.penalize(HardSoftScore.ONE_HARD,
(computer, processList) -> ...)
.asConstraint("computerAndItsProcesses");
}Variants of this collector:
-
toList()collects aListvalue. -
toSet()collects aSetvalue. -
toSortedSet()collects aSortedSetvalue. -
toMap()collects aMapvalue. -
toSortedMap()collects aSortedMapvalue.
|
The iteration order of elements in the resulting collection is not guaranteed to be stable,
unless it is a sorted collector such as |
4.5.2. Conditional collectors
The constraint collector framework enables you to create constraint collectors which will only collect in certain circumstances.
This is achieved using the ConstraintCollectors.conditionally(…) constraint collector.
This collector accepts a predicate, and another collector to which it will delegate if the predicate is true. The following example returns a count of long-running processes assigned to a given computer, excluding processes which are not long-running:
private Constraint computerWithLongRunningProcesses(ConstraintFactory constraintFactory) {
return constraintFactory.forEach(CloudProcess.class)
.groupBy(CloudProcess::getComputer, conditionally(
CloudProcess::isLongRunning,
count()
))
.penalize(HardSoftScore.ONE_HARD,
(computer, longRunningProcessCount) -> ...)
.asConstraint("longRunningProcesses");
}This is useful in situations where multiple collectors are used and only some of them need to be restricted.
If all of them needed to be restricted in the same way,
then applying a filter() before the grouping is preferable.
4.5.3. Composing collectors
The constraint collector framework enables you to create complex collectors utilizing simpler ones.
This is achieved using the ConstraintCollectors.compose(…) constraint collector.
This collector accepts 2 to 4 other constraint collectors,
and a function to merge their results into one.
The following example builds an average() constraint collector
using the count constraint collector and sum() constraint collector:
public static <A> UniConstraintCollector<A, ?, Double>
average(ToIntFunction<A> groupValueMapping) {
return compose(count(), sum(groupValueMapping), (count, sum) -> {
if (count == 0) {
return null;
} else {
return sum / (double) count;
}
});
}Similarly, the compose() collector enables you to work around the limitation of Constraint Stream cardinality
and use as many as 4 collectors in your groupBy() statements:
UniConstraintCollector<A, ?, Triple<Integer, Integer, Integer>> collector =
compose(count(),
min(),
max(),
(count, min, max) -> Triple.of(count, min, max));
}Such a composite collector returns a Triple instance which allows you to access
each of the sub collectors individually.
|
OptaPlanner does not provide any |
4.6. Conditional propagation
Conditional propagation enables you to exclude constraint matches from the constraint stream based on the presence or absence of some other object.
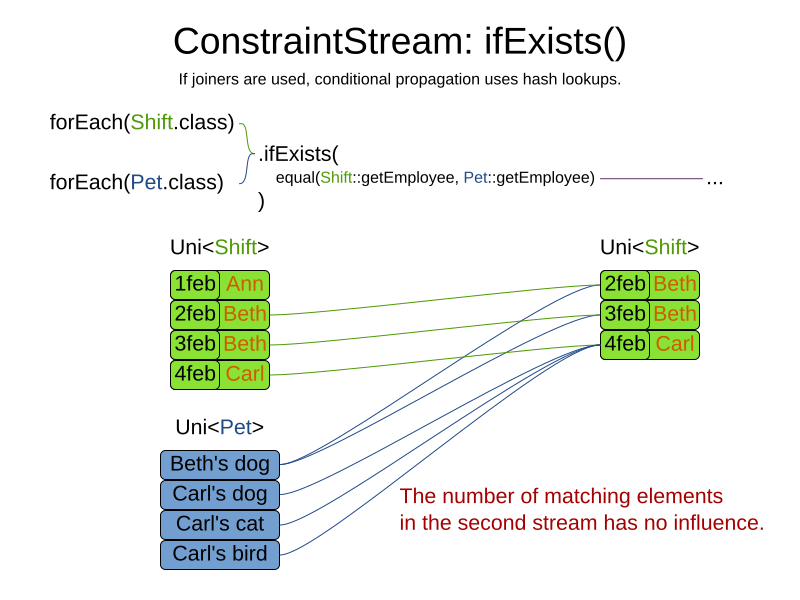
The following example penalizes computers which have at least one process running:
private Constraint runningComputer(ConstraintFactory constraintFactory) {
return constraintFactory.forEach(CloudComputer.class)
.ifExists(CloudProcess.class, Joiners.equal(Function.identity(), CloudProcess::getComputer))
.penalize(HardSoftScore.ONE_SOFT,
computer -> ...)
.asConstraint("runningComputer");
}Note the use of the ifExists() building block.
On UniConstraintStream, the ifExistsOther() building block is also available which is useful in situations where the
forEach() constraint match type is the same as the ifExists() type.
Conversely, if the ifNotExists() building block is used (as well as the ifNotExistsOther() building block on
UniConstraintStream) you can achieve the opposite effect:
private Constraint unusedComputer(ConstraintFactory constraintFactory) {
return constraintFactory.forEach(CloudComputer.class)
.ifNotExists(CloudProcess.class, Joiners.equal(Function.identity(), CloudProcess::getComputer))
.penalize(HardSoftScore.ONE_HARD,
computer -> ...)
.asConstraint("unusedComputer");
}Here, only the computers without processes running are penalized.
Also note the use of the Joiner class to limit the constraint matches.
For a description of available joiners, see joining.
Conditional propagation operates much like joining, with the exception of not increasing the
stream cardinality.
Matches from these building blocks are not available further down the stream.
|
For performance reasons, using conditional propagation with the appropriate |
4.7. Mapping tuples
Mapping enables you to transform each tuple in a constraint stream by applying a mapping function to it.
The result of such mapping is UniConstraintStream of the mapped tuples.
private Constraint computerWithBiggestProcess(ConstraintFactory constraintFactory) {
return constraintFactory.forEach(CloudProcess.class) // UniConstraintStream<CloudProcess>
.map(CloudProcess::getComputer) // UniConstraintStream<CloudComputer>
...
}|
In the example above, the mapping function produces duplicate tuples if two different |
4.7.1. Designing the mapping function
When designing the mapping function, follow these guidelines for optimal performance:
-
Keep the function pure. The mapping function should only depend on its input. That is, given the same input, it always returns the same output.
-
Keep the function bijective. No two input tuples should map to the same output tuple, or to tuples that are equal. Not following this recommendation creates a constraint stream with duplicate tuples, and may force you to use
distinct()later. -
Use immutable data carriers. The tuples returned by the mapping function should be immutable and identified by their contents and nothing else. If two tuples carry objects which equal one another, those two tuples should likewise equal and preferably be the same instance.
4.7.2. Dealing with duplicate tuples using distinct()
As a general rule, tuples in constraint streams are distinct. That is, no two tuples that equal one another. However, certain operations such as tuple mapping may produce constraint streams where that is not true.
If a constraint stream produces duplicate tuples, you can use the distinct() building block
to have the duplicate copies eliminated.
private Constraint computerWithBiggestProcess(ConstraintFactory constraintFactory) {
return constraintFactory.forEach(CloudProcess.class) // UniConstraintStream<CloudProcess>
.map(CloudProcess::getComputer) // UniConstraintStream<CloudComputer>
.distinct() // The same, each CloudComputer just once.
...
}|
There is a performance cost to |
4.8. Flattening
Flattening enables you to transform any Java Iterable (such as List or Set)
into a set of tuples, which are sent downstream.
(Similar to Java Stream’s flatMap(…).)
This is done by applying a mapping function to the final element in the source tuple.
private Constraint requiredJobRoles(ConstraintFactory constraintFactory) {
return constraintFactory.forEach(Person.class) // UniConstraintStream<Person>
.join(Job.class,
equal(Function.identity(), Job::getAssignee)) // BiConstraintStream<Person, Job>
.flattenLast(Job::getRequiredRoles) // BiConstraintStream<Person, Role>
.filter((person, requiredRole) -> ...)
...
}|
In the example above, the mapping function produces duplicate tuples
if |
5. Testing a constraint stream
Constraint streams include the Constraint Verifier unit testing harness.
To use it, first add a test scoped dependency to the optaplanner-test JAR.
5.1. Testing constraints in isolation
Consider the following constraint stream:
protected Constraint horizontalConflict(ConstraintFactory factory) {
return factory
.forEachUniquePair(Queen.class, equal(Queen::getRowIndex))
.penalize(SimpleScore.ONE)
.asConstraint("Horizontal conflict");
}The following example uses the Constraint Verifier API to create a simple unit test for the preceding constraint stream:
private ConstraintVerifier<NQueensConstraintProvider, NQueens> constraintVerifier
= ConstraintVerifier.build(new NQueensConstraintProvider(), NQueens.class, Queen.class);
@Test
public void horizontalConflictWithTwoQueens() {
Row row1 = new Row(0);
Column column1 = new Column(0);
Column column2 = new Column(1);
Queen queen1 = new Queen(0, row1, column1);
Queen queen2 = new Queen(1, row1, column2);
constraintVerifier.verifyThat(NQueensConstraintProvider::horizontalConflict)
.given(queen1, queen2)
.penalizesBy(1);
}This test ensures that the horizontal conflict constraint assigns a penalty of 1 when there are two queens on the same
row.
The following line creates a shared ConstraintVerifier instance and initializes the instance with the
NQueensConstraintProvider:
private ConstraintVerifier<NQueensConstraintProvider, NQueens> constraintVerifier
= ConstraintVerifier.build(new NQueensConstraintProvider(), NQueens.class, Queen.class);The @Test annotation indicates that the method is a unit test in a testing framework of your choice.
Constraint Verifier works with many testing frameworks including JUnit and AssertJ.
The first part of the test prepares the test data.
In this case, the test data includes two instances of the Queen planning entity and their dependencies
(Row, Column):
Row row1 = new Row(0);
Column column1 = new Column(0);
Column column2 = new Column(1);
Queen queen1 = new Queen(0, row1, column1);
Queen queen2 = new Queen(1, row1, column2);Further down, the following code tests the constraint:
constraintVerifier.verifyThat(NQueensConstraintProvider::horizontalConflict)
.given(queen1, queen2)
.penalizesBy(1);The verifyThat(…) call is used to specify a method on the NQueensConstraintProvider class which is under test.
This method must be visible to the test class, which the Java compiler enforces.
The given(…) call is used to enumerate all the facts that the constraint stream operates on.
In this case, the given(…) call takes the queen1 and queen2 instances previously created.
Alternatively, you can use a givenSolution(…) method here and provide a planning solution instead.
Finally, the penalizesBy(…) call completes the test, making sure that the horizontal conflict constraint, given
one Queen, results in a penalty of 1.
This number is a product of multiplying the match weight, as defined in the constraint stream, by the number of matches.
Alternatively, you can use a rewardsWith(…) call to check for rewards instead of penalties.
The method to use here depends on whether the constraint stream in question is terminated with a penalize or a
reward building block.
|
|
5.2. Testing all constraints together
In addition to testing individual constraints, you can test the entire ConstraintProvider instance.
Consider the following test:
@Test
public void givenFactsMultipleConstraints() {
Queen queen1 = new Queen(0, row1, column1);
Queen queen2 = new Queen(1, row2, column2);
Queen queen3 = new Queen(2, row3, column3);
constraintVerifier.verifyThat()
.given(queen1, queen2, queen3)
.scores(SimpleScore.of(-3));
}There are only two notable differences to the previous example.
First, the verifyThat() call takes no argument here, signifying that the entire ConstraintProvider instance is
being tested.
Second, instead of either a penalizesBy() or rewardsWith() call, the scores(…) method is used.
This runs the ConstraintProvider on the given facts and returns a sum of Scores of all constraint matches resulting
from the given facts.
Using this method, you ensure that the constraint provider does not miss any constraints and that the scoring function
remains consistent as your code base evolves.
It is therefore necessary for the given(…) method to list all planning entities and problem facts,
or provide the entire planning solution instead.
|
|
6. Variant implementation types
Constraint streams come in two flavors:
-
CS Drools (default): fast implementation that uses Drools underneath.
-
Bavet: even faster, more recent in-house implementation. To try it out set the
constraintStreamImplTypetoBAVETin your solver config:<solver xmlns="https://www.optaplanner.org/xsd/solver" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="https://www.optaplanner.org/xsd/solver https://www.optaplanner.org/xsd/solver/solver.xsd"> <scoreDirectorFactory> <constraintProviderClass>org.acme.schooltimetabling.solver.TimeTableConstraintProvider</constraintProviderClass> <!-- BAVET is experimental --> <constraintStreamImplType>BAVET</constraintStreamImplType> </scoreDirectorFactory> ... </solver>
Both of these variants implement the same ConstraintProvider API.
No Java code changes are necessary to switch between the two.